llms.txt não basta: a arquitetura que vem depois para sua marca virar fonte da IA
Mais do que um arquivo em Markdown, marcas precisam de uma estrutura com dados, relações, APIs e proveniência para alimentar agentes de IA.
O llms.txt virou assunto porque acerta no diagnóstico: os sites de hoje foram montados para pessoas, não para agentes de IA. Só que muita gente está tratando esse arquivo como solução final, quando ele é, na prática, só o começo da conversa.
Colocar um llms.txt no ar ajuda. Ele funciona como uma espécie de índice limpo, uma porta de entrada mais organizada para o que sua marca publica. O problema é achar que isso resolve tudo. Não resolve.
Para uma marca que vende produto, compara planos, atualiza preço, muda funcionalidade, publica FAQ, case, documentação e posicionamento oficial, um simples diretório em Markdown é pouco. O que a IA precisa de verdade não é só de uma lista de links. Ela precisa de acesso limpo, estruturado, atual, verificável e com contexto.
O llms.txt ajuda, mas para no meio do caminho
O mérito do llms.txt é reduzir ruído. Em vez de obrigar um modelo a navegar por menu, banner, script, pop-up e JavaScript quebrado, ele oferece um caminho mais simples até o conteúdo principal. Para documentação técnica, referência de API e conteúdo mais estático, isso já tem utilidade.
Mas, quando a operação fica mais complexa, ele começa a mostrar limite. O arquivo não explica bem relações entre entidades. Ele não deixa claro, por exemplo, que um plano pertence a uma família de produtos, que uma funcionalidade foi descontinuada, que outra entrou no lugar, que um porta-voz é a fonte mais confiável para determinado assunto ou que um preço mudou ontem à noite.
Em resumo: o llms.txt mostra o que existe, mas não explica direito como as coisas se conectam. E é justamente nessa falta de contexto que mora boa parte das respostas erradas, superficiais ou "confiantes demais" que a IA costuma dar.
Tem ainda um problema operacional. Se cada mudança estratégica exigir atualizar a página oficial e também um arquivo paralelo, você cria mais uma camada manual para manter. Em empresa pequena isso até passa. Em operação grande, com time distribuído, vira dívida técnica e editorial.
O que vem depois: a pilha que faz a IA entender sua marca
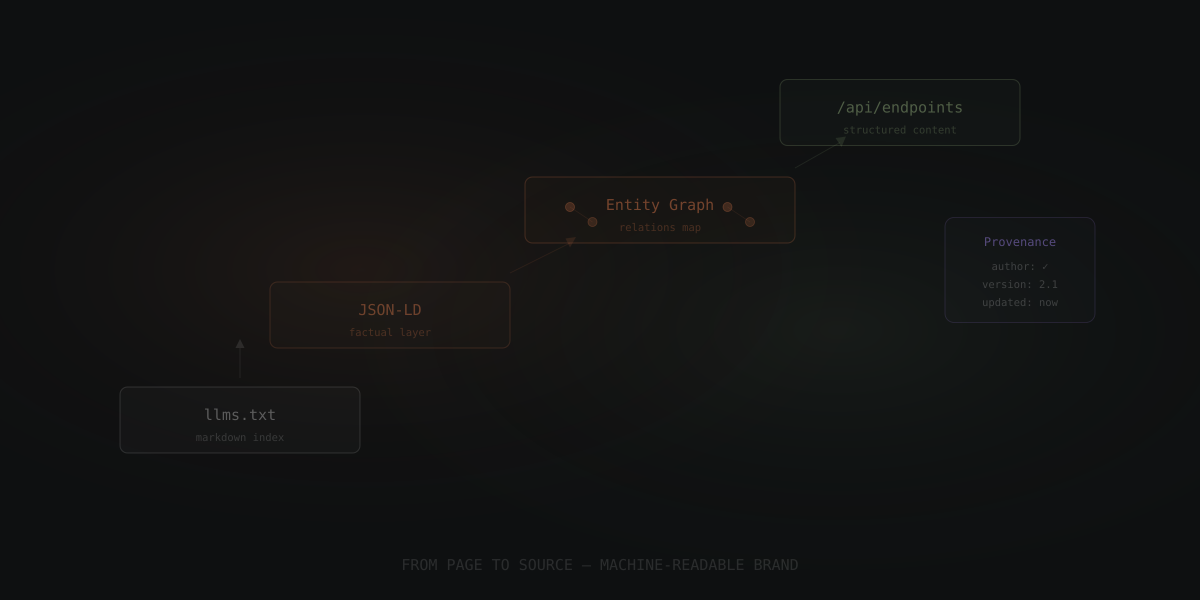
O caminho mais sólido é pensar em uma arquitetura legível por máquina. Não como substituição do llms.txt, mas como a próxima etapa. Algo parecido com o que aconteceu na web quando robots.txt deixou de ser suficiente e vieram sitemap, schema e outras camadas de estrutura.
Primeira camada: fichas factuais com JSON-LD. Aqui entra o básico bem feito. Organização, produto, serviço, FAQ, review, autor, disponibilidade, preço, data de atualização. Não como truque para rich snippet, mas como uma camada oficial de fatos que a máquina consegue ler sem precisar adivinhar.
Segunda camada: mapa de relações entre entidades. Não basta dizer que uma página existe. É preciso mostrar que o Produto A pertence à Categoria B, que a Integração C atende ao Caso de Uso D, que a Feature E só existe no plano enterprise, e que tudo isso aponta para uma fonte oficial. A IA responde melhor quando navega por relações, não por páginas soltas.
Terceira camada: endpoints de conteúdo estruturado. Esse é o ponto em que a estratégia sai do "site bonito" e entra em infraestrutura de verdade. Em vez de deixar a IA inferir informação de uma página renderizada em JavaScript, você entrega um endpoint com dado organizado, atualizado, versionado e atribuível. Um /api/precos, um /api/faq, um /api/comparativo. Isso muda o jogo.
Quarta camada: verificação e proveniência. Toda informação importante deveria carregar carimbo de origem: quem publicou, quando foi atualizado, qual é a versão e de onde veio o dado. Quando dois conteúdos entram em conflito, esse tipo de metadado ajuda a IA a decidir em quem confiar.
Na prática, isso muda o que a IA responde sobre você
Pensa em uma empresa brasileira de software de gestão vendendo para PMEs e grandes contas. Ela tem três planos, dezenas de integrações, páginas comerciais bonitas, comparativos em PDF e FAQs espalhados pelo site.
Hoje, para um comprador humano, isso pode funcionar muito bem. Para um agente de IA fazendo pesquisa de fornecedor, nem tanto. Se o preço está escondido em JavaScript, se o comparativo principal está em PDF e se as integrações estão espalhadas em páginas sem estrutura, a tendência é a IA errar. Ela pode confundir preço, omitir recurso enterprise ou deixar passar justamente a integração que o cliente precisa.
Com uma arquitetura legível por máquina, o cenário muda. A página comercial continua existindo para o humano, mas por baixo dela existe uma camada confiável para a IA consumir. O preço vem da mesma fonte do CMS. As funcionalidades estão amarradas ao plano correto. As integrações aparecem agrupadas por solução. O FAQ sai por endpoint estruturado. E cada fato traz data, dono e versão.
Resultado: a IA para de "achar" e passa a recuperar informação oficial. E isso reduz um risco que muita marca ainda subestima: perder venda, reputação e contexto porque um agente respondeu errado sobre algo que estava no seu próprio site.
O melhor momento para começar não é quando o padrão estiver perfeito
É verdade que esse ecossistema ainda está se formando. O llms.txt ainda é uma proposta. O MCP ganhou força, mas o padrão definitivo de troca entre marca e agente ainda está amadurecendo. Mesmo assim, esperar tudo ficar "oficial demais" pode ser o erro.
Quem saiu na frente com dados estruturados no começo da década passada ajudou a moldar a forma como buscadores passaram a consumir informação. Agora, a lógica é parecida. As marcas que estruturarem cedo seus fatos, relações e fontes tendem a influenciar como os agentes vão consumir isso amanhã.
O mínimo viável já dá para fazer sem loucura: auditar o JSON-LD das páginas mais importantes, criar um endpoint estruturado para preço e recursos centrais e adicionar metadados de atualização e autoria nas informações públicas mais críticas.
Isso é muito mais útil do que publicar uma cópia em Markdown do site e torcer para algum robô entender tudo sozinho. No fim, a discussão não é sobre ter ou não ter llms.txt. É sobre algo maior: sua marca vai continuar sendo lida como página ou vai passar a ser entendida como fonte?
Quer ver o atalay.ia na sua redação?
Solicitar demonstração